תקציר-סבתא של המאמר מאת הדר אפודי-קלרמן ודרור דותן (קישור למאמר)
A phonological input buffer for numbers
כמה קשה זה להקשיב למספר ולהבין אותו?
אולי זה נראה לך כמו משהו קל אבל האמת היא שזה לא עד כדי כך פשוט. אפילו כשמדובר במטלה פשוטה שדורשת הבנת מספרים מתוך שמיעה – למשל, אומרים לך מספר (למשל ״שלושים ושבע אלף וחמש״) וצריך לכתוב אותו על דף (37,005). אפילו אנשים בלי לקויות עושים לא מעט טעויות במטלה הזאת – בערך טעות אחת כל 20 מספרים.
לא תופתעו לשמוע שרוב הטעויות מופיעות במספרים ארוכים (עם הרבה ספרות/מילים). למה דווקא בהם? יש לכך כמה סיבות, ואחת החשובות שבהן היא שקשה יותר לזכור מספר ארוך. במטלת ההכתבה, עובר פרק זמן מסוים בין הרגע בו שמענו את המספר עד הרגע בו כתבנו אותו על הדף. במשך הזמן הזה אנחנו צריכים להחזיק את המספר בזיכרון לטווח קצר, וזיכרון לטווח קצר זה עסק ביש. הוא יודע לשמור כמות די קטנה של מידע, והוא נוטה להתבלבל.
אוקיי, אז צריך זיכרון לטווח קצר במטלת הכתבה. זה כשלעצמו די טריוויאלי. השאלה היותר-מעניינת, והיא זו שבדקנו במחקר הזה, היא איזה מין זיכרון זה, איך הוא עובד, ואיך הוא משתלב בתהליך עיבוד המספר.
כדי לגלות את הדברים האלה, חקרנו את NANI ו-BIMA – שני אנשים בני 30 פלוס, שהזיכרון לטווח קצר שלהם לקוי כך שהקיבולת שלו מצומצמת: אדם ממוצע יכול לשמוע רצף של עד כ-7 ספרות אקראיות ולחזור עליהן בלי טעויות, אבל NANI ו-BIMA מסוגלים לחזור על מכסימום 5 ספרות. לא תופתעו לשמוע שהם עשו הרבה טעויות בהכתבה של מספרים רב-ספרתיים. העברנו להם עוד לא מעט מטלות עיבוד מספרים, וגילינו כמה דפוסים מעניינים שעזרו לנו לאבחן באופן מדויק מה בדיוק המנגנון הלקוי אצלם. למשל:
- הם עשו הרבה טעויות בכל המטלות בהן הם שמעו את המספר. בניגוד לכך, לא היתה להם בעיה במטלות בהן הקלט לא היה שמיעתי (למשל: לקרוא מספרים בקול, להגיד מה תאריך הלידה שלהם וכו׳). מכך הסקנו שהליקוי שלהם נמצא איפשהו במנגנונים של הקלט השמיעתי.
- הם עשו הרבה טעויות במטלות שמיעת-מספרים כל עוד המטלה יצרה עומס על הזיכרון לטווח קצר. אבל במטלות דומות בלי עומס זיכרון – הם לא טעו. זה מראה שהטעויות לא נובעות מליקוי בשמיעה או בהבנה, אלא נובעות ספציפית מליקוי בזיכרון לטווח קצר.
דפוסים התוצאות הנ״ל של NANI ו-BIMA, ועוד כמה ממצאים שלא פירטנו כאן (כדי לקצר), הראו שהליקוי שלהם הוא במנגנון זיכרון לטווח קצר שנמצא בשלב הקלט השמיעתי-מילולי. קראנו למנגנון הזה ״באפר קלט פונולוגי״. כרגיל במחקרים מהסוג הזה, יש פה בעצם שתי מסקנות מעניינות: אחת, שבאפר הקלט הפונולוגי קיים (אם הוא לא קיים, הוא לא יכול להיות לקוי). השניה, שייתכן מצב של ליקוי סלקטיבי בבאפר הזה, בלי ליקוי במנגנונים אחרים של עיבוד מספרים.
השלב הבא במחקר היה לא פחות מעניין: ניסינו להבין איך הבאפר הזה בדיוק עובד – ספציפית, מתי ובשביל מה צריך אותו. הטריק פה פשוט: אם יש לנבדקים שלנו ליקוי בבאפר הקלט הפונולוגי, אז הם יתקשו במטלות שמחייבות שימוש בבאפר הזה, ולא יתקשו במטלות שלא מחייבות שימוש בו.
גילינו ש- NANI ו-BIMA מתקשים במיוחד כאשר משמיעים להם מספרים רב-ספרתיים (״אלפיים שלוש מאות ארבעים וחמש״) אבל פחות מתקשים כשמשמיעים להם רצף מילות מספר בודדות (״שתיים, שלוש, ארבע, חמש״). כלומר, באפר הקלט הפונולוגי מהווה ״צוואר בקבוק״ לגבי מספרים רב-ספרתיים אבל לא לגבי ספרות בודדות. המסקנה היא שאחד התפקידים החשובים של באפר הקלט הפונולוגי הוא לסייע בעיבוד שמיעתי של מספר רב-ספרתי.
כדי להבין אינטואיטיבית למה זה הגיוני, חשבו על הדוגמה הפשוטה הבאה: אם שמעתם את המילה ״ארבע״ כחלק מרצף מילות-מספר בודדות, אתם לא חייבים להחזיק אותה הרבה זמן בזיכרון – אפשר לדעת מייד שזה 4. אבל אם שמעתם את המילה הזאת כחלק ממספר רב-ספרתי, חייבים לחכות עד המילה הבאה כדי לדעת אם זה 4, 400 או 4000, ולחכות אפילו יותר כדי לדעת אם זה 400 או 400,000. ובזמן שמחכים, צריך להחזיק את המילה ״ארבע״ בזיכרון לטווח קצר.
המסקנות הנ״ל, יחד עם עוד כמה מסקנות שלא פירטנו כאן (למשל מעבודת התזה של זהר כהן), איפשרו לנו להבין באופן די מפורט מה השלבים בהבנה של מספרים מתוך שמיעה:
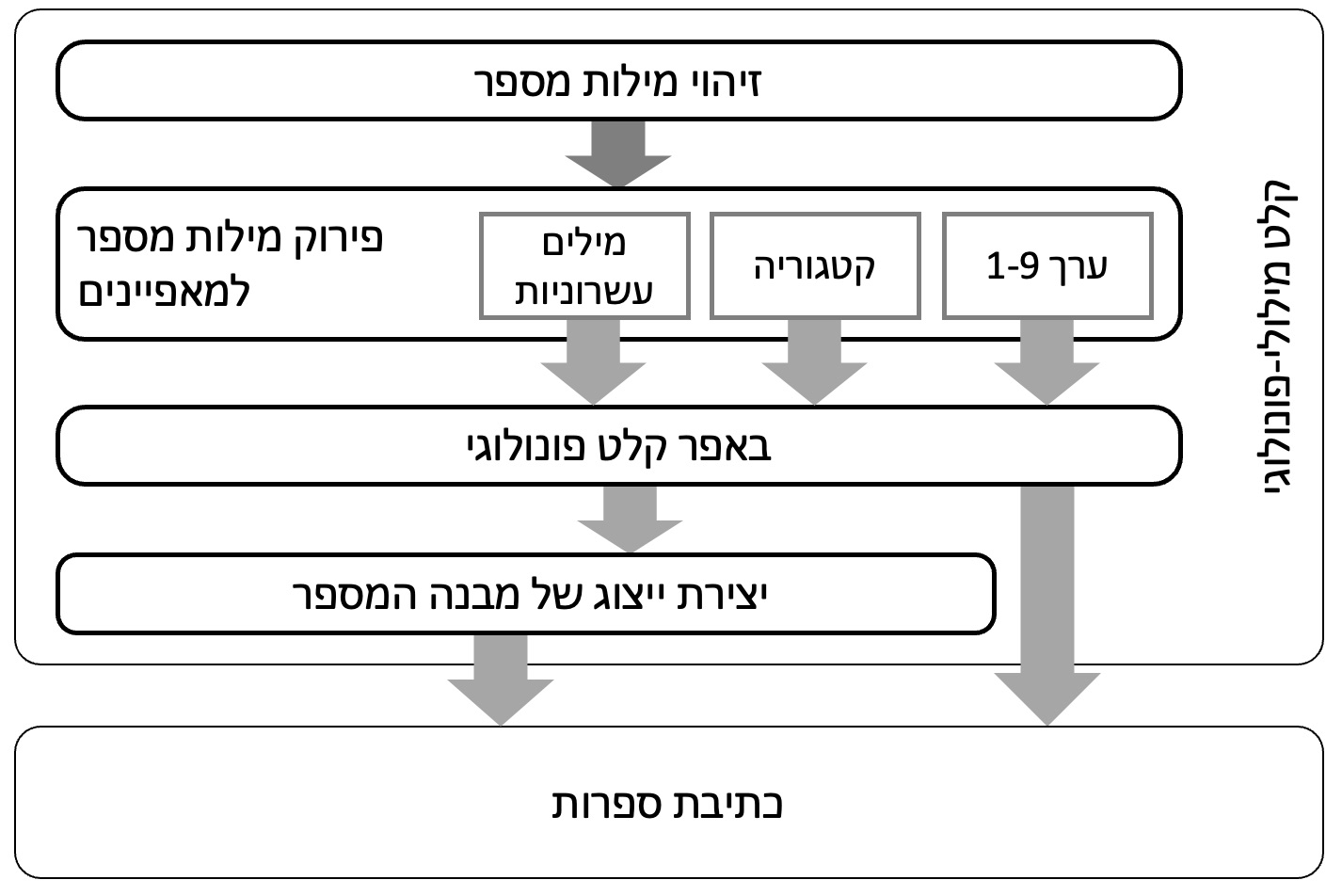
השלבים המעורבים בהבנת מספר מילולי משמיעה: שלב (1) הוא זיהוי כל מילת המספר. שלב (2) מפרק כל מילה למרכיביה: מילים כמו ״עשרים״ מפורקות ל-2 מאפיינים (ערך 1-9, במקרה זה 2; והקטגוריה, במקרה זה עשרות). המילה העשרונית ״אלף״ (ובאנגלית גם ״hundred״) מיוצגת כמאפיין אחד. שלב (3) הוא באפר הקלט הפונולוגי – רכיב זיכרון לטווח קצר ששומר את מאפייני המילה. בשלב (4) נוצר ייצוג שמתאר את המבנה המלא של המספר הרב-ספרתי, ובעצם משייך כל מילה לתפקיד המתאים שלה במספר ביחס לשאר המילים. ייצוג זה משמש את מנגנוני הפלט כדי ליצור את רצף הספרות המתאים ולכתוב אותו.