תקציר-סבתא של המאמר מאת דרור דותן
Top-down number reading: Language affects the visual identification of digit strings
קראו את הקטע הקצר הזה מתוך ספר הילדים ״מיץ פטל״ (מאת חיה שנהב):
ואז – נפתחה הדלת,
והם ראו רגל לבנה, ועוד רגל לבנה,
שתי אוזניים לבנות ארוכות,
גוף קטן ולבן,
הם עמדו בשקט-בשקט ולא צעקו.
והנה סוף סוף – מיץ פטל הארנב!!!
אחרי הקריאה, הביטו – מה רואים בתמונה הזאת:

בטח חלקכן.ם כבר הכירו את התמונה הזאת, היא די ידועה. ובכל זאת, איזו חיה ראית?
כנראה שראית ארנב. ואולי מייד אחרי זה ראית גם את הברווז (אם לא ראית: הארנב מסתכל על הגזר אבל הברווז מסתכל שמאלה ולמעלה, והמקור שלו הוא האוזניים של הארנב).
למה ראית קודם את הארנב ולא את הברווז? יש הרבה גורמים שמשפיעים על זה. למשל, איך התמונה מצוירת. אבל עוד גורם שמשפיע כאן הוא הציור של הגזר, והטקסט מהסיפור על מיץ פטל הארנב, וזאת הפואנטה של הדוגמה הזאת: ההקשר בו ראינו את התמונה משפיע על האופן בו נבין אותה.
תחשבו על זה רגע – זה ממש לא מובן מאליו. נראה לי שהאינטואיציה של רובנו לגבי מערכת הראייה האנושית היא שזו מערכת שעובדת באופן שאנחנו נוהגים לקרוא לו bottom up. לפי הסיפור הזה, הראייה מתחילה כשהאור שמוחזר ממסך המחשב או הטלפון מגיע לעין שלך; המידע הוויזואלי הזה נקלט ברשתית; הוא עובר לאיזור העיבוד הוויזואלי הראשוני במוח, שמזהה את האלמנטים הבסיסיים בתמונה (קווים, משטחים וכו׳); בשלב הבא אולי מזהים תמונה של משהו שאנחנו מכירים; ובסוף קופצת גם המילה: ״ארנב״. נכון?
אז זהו, שזה לא נכון. הראייה, ולא מעט מערכות תפיסתיות אחרות, עובדות כמובן גם בצורה שתיארנו למעלה, אבל לא רק. כן, יש מידע ויזואלי שזורם ״קדימה״, מהעין לאיזור הראייה לאיזורי העיבוד ה״גבוהים״ יותר של המוח. אבל יש גם מידע שזורם בחזרה, ועוזר למנגנונים הוויזואליים הראשוניים ״לכוון״ את עצמם בהתאם לציפיות שלנו. אם אנחנו מצפים לראות ארנב, זה מגדיל את הסיכוי שנראה ארנב. אנחנו קוראים לזה עיבוד top-down. זה מעניין כי זה קצת מספר לנו איך המוח שלנו והתפיסה שלנו עובדים. אם נדמה את עצמנו למחשב, אז אנחנו לא מחשב עם מעבד נורא מתוחכם שיושב באמצע ומקבל מידע מהמון חיישנים פשוטים שמחוברים אליו. אנחנו יותר דומים למחשב בו גם החיישנים הם מאד חכמים, והשיח בינם לבין המעבד המרכזי הוא לא חד-סיטרי אלא דו סיטרי.
אז איך כל זה קשור לאופן בו אנחנו קוראים מספרים?
בעולם של הראייה והחושים, אנחנו כבר יודעים מזמן שהסיפור מורכב, והמערכות התפיסתיות עובדות בשילוב של זרימת מידע bottom-up ו-top-down. אבל דווקא כשאנחנו מדברים על פעולות קוגניטיביות מורכבות יותר, כמו קריאת מספרים ושפה – דווקא שם התפיסות המקובלות מתארות את התהליך באמצעות הסיפור הפשוט-יותר, של bottom-up.
בקריאת מספרים, אפילו אנחנו כאן סיפרנו לכם – באחד מתקצירי הסבתא הקודמים – סיפור מהסוג הזה, שאומר את הדבר הבא: כשאנחנו קוראים מספרים בקול, העסק מתחיל בעיבוד ויזואלי של רצף הספרות – כלומר לזהות את הספרות, את הסדר שלהן וכו׳; וזה ממשיך עם רצף של כמה שלבי עיבוד, שבסופם אנחנו אומרים את מילות המספר המתאימות. הסיפור הזה נכון, אבל כמו בדוגמת הארנב-ברווז, זה לא הסיפור המלא. אז היום אני רוצה לספר לכם.ן על אחד המחקרים שלנו שהראו את זה.
השאלה הבסיסית של המחקר הזה היתה: האם בקריאת מספרים יש תהליכי top-down? כלומר, בנוסף לכך שהנתח הוויזואלי, אותו תהליך שמעבד את רצף הספרות, ״שולח״ מידע למנגנוני הפקת המילים, מתקיים גם הכיוון ההפוך: מנגנוני הדיבור (הפקת מילים) שולחים מידע בחזרה אל הנתח הוויזואלי ו״מכוונים״ את הפעולה שלו, ממש כמו שהקונטקסט של ארנב כנראה כיוון את התפיסה הוויזואלית שלנו. כדי לבדוק את זה, התמקדנו בתכונה בספציפית של הנתח הוויזואלי – זה שהוא סורק את הספרות משמאל לימין. שאלנו למה הוא סורק את הספרות דווקא משמאל לימין. סיבה אפשרית אחת היא שמדובר בתכונה ״פנימית״ של הנתח הוויזואלי עצמו. אבל סיבה אפשרית שניה, שבסיפור שלנו היא המעניינת-יותר (ובמקרה גם הנכונה), היא שסדר סריקת הספרות לא נקבע רק ע״י הנתח הוויזואלי עצמו, אלא גם ע״י מנגנוני הפקת המילים, שמשפיעים על הנתח הוויזואלי באמצעות תהליכי top-down. ולמה שמנגנוני הפקת המילים ירצו שהנתח יסרוק את הספרות משמאל לימין? כי זה תואם בדיוק את הסדר בו אנחנו אומרים את מילות המספר. למשל במספר 123 אנחנו אומרים קודם ״מאה״, אחר כך ״עשרים״ ובסוף ״שלוש״. אז למערכת הדיבור נוח אם הנתח הוויזואלי סורק את הספרות בסדר הנכון ומעביר לה את האינפורמציה לגבי הספרות בסדר בו היא רוצה לקבל אותן.
כדי לבדוק מי משתי האפשרויות נכונה, הלכנו לבדוק איך קוראים מספרים בערבית. בשפה הערבית, אומרים את מילות המספר בסדר שונה מעברית: מילת היחידות קודמת למילת העשרות. לדוגמה, 32 זה ״תנין ות׳לאתין״ (שתיים ושלושים), ו-54,321 זה ״ארבע וחמישים אלף, שלוש מאות אחד ועשרים״ (אגב, גם עברית עתיקה איפשרה סדר מילים הפוך: כזכור, המלך אחשוורוש שלט על שבע מאה ועשרים מדינה). אם הסיפור של תהליכי top-down נכון, הנתח הוויזואלי של דוברי ערבית אמור לסרוק את ספרת היחידות לפני ספרת העשרות, בניגוד למצב אצל דוברי עברית.
איך נדע באיזה סדר הנתח הוויזואלי סורק את הספרות? לקחנו שיטה שכבר השתמשנו בה בעבר: המשתתפים בניסוי הקריאו מספרים בקול, אבל כל מספר הוצג לזמן מאד קצר (פחות מרבע שניה). במצב כזה, הנתח הוויזואלי לא תמיד מספיק להגיע לספרות האחרונות (כלומר אל אלה שהוא סורק אחרונות), ואז יש יותר טעויות באותן ספרות. כלומר, ככל שאנחנו מוצאים יותר טעויות בספרה מסוימת, אנחנו מבינים שהנתח הוויזואלי סרק אותה מאוחר יותר.
אז עכשיו אנחנו טוענים את הדבר הבא: אם הנתח הוויזואלי מושפע מאופן אמירת המילים בשפה, אנחנו מצפים להבדל בין דוברי העברית לדוברי הערבית. בהשוואה לעברית, דוברי הערבית יצליחו קצת יותר בספרת היחידות וקצת פחות בספרת העשרות. שימו לב שלא איכפת לנו כרגע מה יהיה ההבדל הכללי בין עשרות ליחידות, או ההבדל הכללי בין עברית לערבית (כי יש עוד גורמים שמשפיעים על ההבדלים האלה). מעניינת אותנו רק ההשערה הספציפית שיהיו דפוסים שונים בין דוברי עברית לערבית. וזה בדיוק מה שקרה:
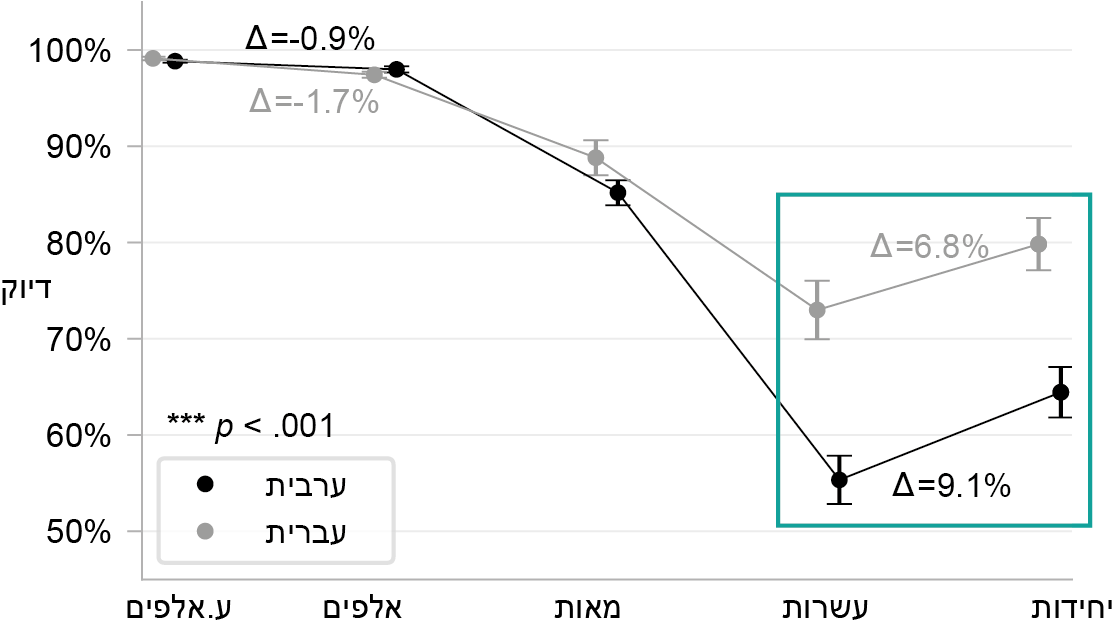
תוצאות הניסוי – אחוז הדיוק בכל ספרה לפי המיקום שלה, בנפרד לעברית וערבית. הממצא הקריטי נוגע להבדל בין השפות ברמת הדיוק של היחידות והעשרות. בשתי השפות יש זיהוי טוב יותר של ספרת היחידות (כנראה כיוון שהיא בקצה), ועדיין, בערבית ההבדל בין היחידות לעשרות גדול יותר מעברית. כלומר, יחסית לעברית, בערבית רמת הדיוק בספרת היחידות גבוהה יותר ובספרת העשרות נמוכה יותר.
וזה לא הכל: בדקנו גם אנשים דו-לשוניים – הם קראו את אותם מספרים פעם בעברית ופעם בערבית. שוב מצאנו את אותו הבדל בין עברית לערבית. כלומר, זה לא סתם שהשפה משפיעה על הנתח הוויזואלי; היא משפיעה עליו באופן נקודתי, בכל רגע נתון, לפי השפה שאנחנו מדברים כרגע.
המחקר הזה מראה לנו שגם בקריאת מספרים פועלים תהליכי top-down. הוא גם מראה לנו שהשפה משפיעה על הרבה ממנגנוני-החשיבה שלנו, כולל כאלה שאנחנו לפעמים חושבים שהם לא מנגנונים שפתיים, למשל ראייה של רצף ספרות. אנחנו גם מרוצים מזה שהמחקר הזה מראה לנו קצת יותר טוב איך באמת עובדים המנגנונים של קריאת מספרים: כמו שסיפרנו במחקר אחר, לקרוא מספרים זה קשה, ובערבית – עם היפוך המילים – זה עוד יותר קשה. ככל שאנחנו מבינים יותר טוב איך קריאת מספרים עובדת במוח שלנו, אנחנו מתקרבים לאפשרות להפוך את הלמידה של זה להיות קלה יותר.
רוצים לקרוא יותר פרטים? המאמר המלא נמצא כאן.